
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- react
- AWS
- back-end
- Sequelize
- spring boot
- swagger
- 코틀린
- state
- 조건문
- java
- class
- 개발이 취미인 사람
- 개발자
- component
- Producer
- props
- Nest.js
- 반복문
- 상속
- jpa
- vue
- file upload
- Kotlin
- kafka
- node.js
- restful api
- front-end
- javascript
- It
- SWIFT
- Today
- Total
개발이 취미인 사람
[Kafka] - 기본 개념 본문
개요
안녕하세요. 이번 시간에는 Apache Kafka의 대해 알아보겠습니다.
Apache Kafka(이하: 카프카)는 아파치 재단에서 만든 오픈소스 메시지 브로커 프로젝트입니다.

위 그림은 메시지 브로커 기본적인 구조를 보여줍니다.
Producer는 메시지를 생성하고 메시지를 Queue로 전송하는 역할을 합니다.
Consumer는 Queue에 적재된 메시지를 가져와서 처리하는 역할을 합니다.
Kafka는 위 구조로 높은 처리량과 낮은 지연시간을 통해 대량에 메시지를 빠르게 처리합니다.
아파치 재단은 Apache Web Server, HBase, Spark, Cassandra, Hadoop 등 정말 다양한 프로젝트를 만들어서 제공해 주는 엄청난 재단입니다. 해당 프로젝트를 안 사용하는 IT 회사는 없다고 생각합니다.
카프카에 대한 상세한 내용은 공식 홈페이지를 꼭 한번 참고해 보는 걸 추천드리겠습니다. 제가 정리하는 내용보다 상세한 내용들이 다 남겨져 있기 때문에 부족한 부분은 공식 홈페이지에서 ㅎㅎ...
기본 개념
카프카를 구성하는 기본적인 개념들은 다음과 같습니다.
- 주키퍼(Zookeeper)
- 카프카 클러스터(Kafka cluster)
- 브로커(Broker)
- 토픽(Topic)
- 파티션(Partition)
- 리플리케이션(Replication)
- 레코드(Record)
- 프로듀서(Producer)
- 세그먼트(Segment)
- 컨슈머(Consumer)
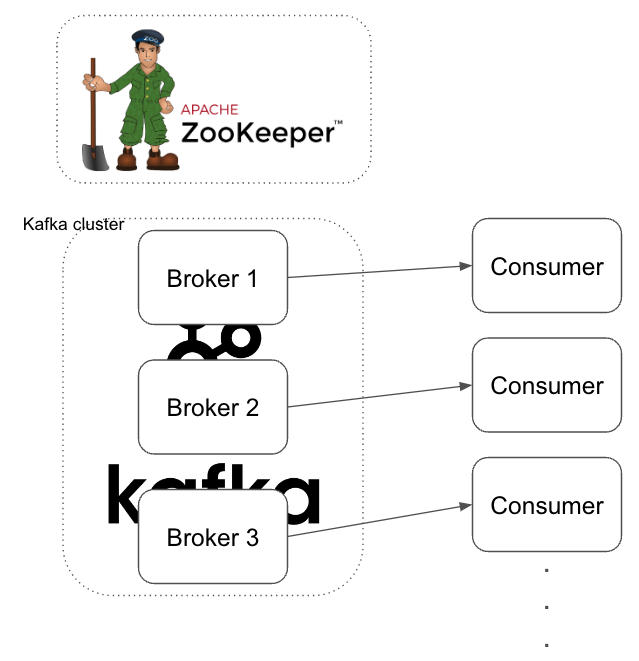
주키퍼(Zookeeper)
주키퍼는 카프카 클러스터를 관리해 주는 코디네이터라고 설명할 수 있습니다.
카프카 서버의 메타데이터(metadata) 관리 및 클러스터 상태 체크(health check)를 리더 선출 등을 관리합니다.

위 이미지와 같이 주키퍼 서버는 여러 카프카 서버를 관리합니다. 카프카는 분산 시스템 구조로 구성되어 있기 때문에 고가용성을 보장합니다. 하나의 서버가 다운되어도 다른 서버가 대신 역할을 수행하기 때문에 서비스 안정성이 높습니다.
보통 마스터와 미러 같은 용어를 사용하지만 카프카에서는 리더(Leader)와 팔로워(Follower)라고 부릅니다.
카프카 클러스터(Kafka cluster)
카프카 클러스터는 여러 대의 Kafka Broker로 구성된 시스템으로 데이터를 분산하여 저장하고 고가용성 및 확장성을 제공하는 메시징 시스템입니다.
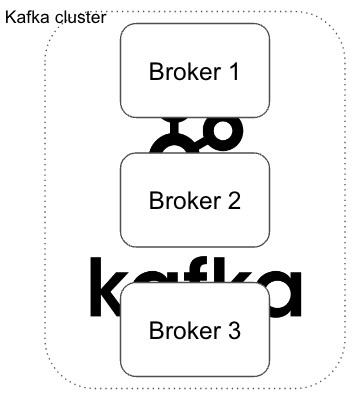
리더 Broker1와 팔로워 Broker2, Broker3이 존재한다고 가정했을 때 리더 서버에서 장애가 발생하면 Zookeeper에서는 리벨런싱 기능을 통해서 새로운 리더 Broker를 선점합니다. 그렇기 때문에 실제 장애가 발생해도 문제가 없이 동작합니다.
(데이터 복제와 여러 가지 상세한 기능은 다른 주제에서 설명을 하겠습니다.)
브로커(Broker)
브로커는 Kafka 서버의 역할을 하는 노드라고 말할 수 있습니다.
각 브로커는 토픽과 해당 토픽의 파티션을 관리하고 클러스터 내에서 데이터를 주고받는 역할을 합니다.
토픽(Topic)
토픽은 카프카에서 데이터를 구분하기 위한 주제라고 정의할 수 있습니다.
예를 들어 로그 데이터, 주문 데이터, 결제 데이터 등 각각의 주제로 구분할 수 있습니다.
또한 토픽 이름을 생성할 때 마침표(.), 언더바(_), 하이픈(-)을 넣어서 생성할 수 있고 이름 짓기 할 때 보통 연관성이 있는 프로젝트나 도메인 이름, 환경, 이벤트 또는 기능 이름을 조합해서 생성합니다.
예를 들어 결제 도메인에서 결제 서비스를 담당하는 파티션을 만든다고 가정한다면 다음과 같이 생성해 볼 수 있을 것 같습니다.
<환경>.<프로젝트명 또는 도메인명>.<이벤트명>.<기능>
prod.payment.request-payment.pay
각 팀이 생각하는 규칙을 만들어서 관리하는 게 중요한 포인트라고 설명할 수 있습니다. 꼭 위 내용은 정답은 아닙니다. :)
파티션(Partition)
파티션은 토픽 안에서 각 주제에 맞는 카테고리라고 정의할 수 있습니다.
예를 들어 로그 데이터라는 큰 주제 아래에는 사용자 활동 데이터, 에러 발생 데이터 등 로그 데이터라는 큰 토픽 하위로 여러 파티션으로 구분할 수 있습니다.
또한 파티션은 전략에 따라 하나의 토픽 안에 여러 파티션을 만들어서 병렬로 데이터를 처리할 수 있습니다.
(파티션 전략과 같은 내용들은 다른 주제에서 설명하겠습니다.)
리플리케이션(Replication)
카프카에서는 리플리케이션(Replication)이라는 기능을 통해 각 메시지들을 여러 개로 복제해 카프카 클러스터 내 브로커들에게 전달하여 메시지를 분산시키는 동작을 의미합니다.
리플리케이션 동작 덕분에 하나의 브로커가 종료되어도 새로운 리터 브로커가 메시지 정보를 알고 있기 때문에 안정성을 유지할 수 있습니다.
카프카의 데이터 복제는 파티션 단위로 복제가 됩니다. (토픽 단위가 아님... 오해 X)
토픽을 생성할 때 파티션의 복제 개수를 설정할 수 있습니다. replication factor이라는 명령어를 통해 설정합니다.
예를 3대의 브로커 서버가 존재한다면 --partition 1, --replication-factor 3이라는 옵션을 추가해서 토픽을 생성하면 아래 그림과 같은 환경이 만들어집니다.
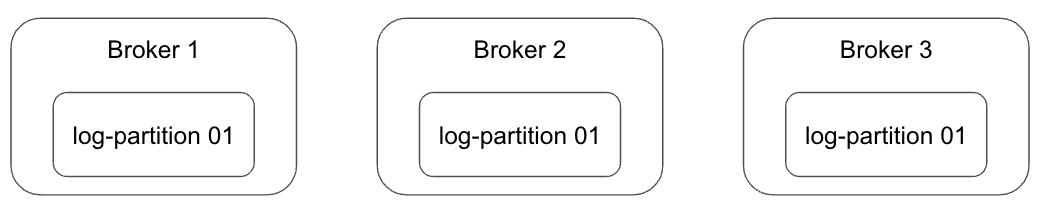
레코드(Record)
레코드는 카프카에서 데이터를 전송하는 기본 단위를 말합니다. 실제 레코드는 파티션에 적제 되어 우리가 사용하게 됩니다.
레코드의 구성요소는 다음과 같습니다.
- 메시지 키
- 메시지 값
- 타임스탬프
- 오프셋
1. 메시지 키는 파티션 내에서 레코드를 그룹화하기 위해 설정합니다.
보통 하나의 파티션을 사용하면 의미가 없지만 만약 두 개 이상에 파티션을 구성하고 있다면 메시지 키를 통해 특정 파티션으로 메시지를 전송할 수 있습니다. 메시지 키는 해쉬 키로 해싱되어 저장되어 우리는
만약 null이라면 파티셔너에 따라서 파티션을 분배해서 메시지를 적재합니다. 현재 기본 설정은 라운드 방식으로 알고 있습니다.
(파티션 전략과 같은 내용들은 다른 주제에서 설명하겠습니다.)
2. 메시지 값은 실질적으로 처리할 데이터입니다.
메시지 키와 메시지 값은 직렬화되어 브로커에 전송됩니다. 그렇기 때문에 메시지 직렬화와 역직렬화 방식은 동일한 방식으로 설정해야 합니다. 그렇지 않다면 문제가 발생하겠죠?...
3. 프로듀서가 생성한 레코드가 브로커로 전송되면 오프셋과 타임스탬프가 지정되어 저장됩니다.
브로커에 한번 적제된 레코드는 수정할 수 없고 로그 리텐션 기간 또는 용량에 따라 삭제됩니다.
타임스탬프는 프로듀서에서 해당 레코드에 생성된 시점을 유닉스 타임으로 설정됩니다.
하지만 프로듀서가 레코드를 생성할 때 임의의 타임스탬프 값을 설정할 수 있고, 토픽 설정에 따라 브로커에 적재 된 시간(LogAppendTime)으로 설정될 수 있다는 점을 유의해야 한다.
왜냐면 컨슈머는 레코드의 타임스탬프를 토대로 레코드가 언제 생성되었는지 알 수 있기 때문이다.
프로듀서(Peroducer)
프로듀서는 카프카 시스템에서 메시지를 특정 파티션에 전송하는 역할을 합니다.
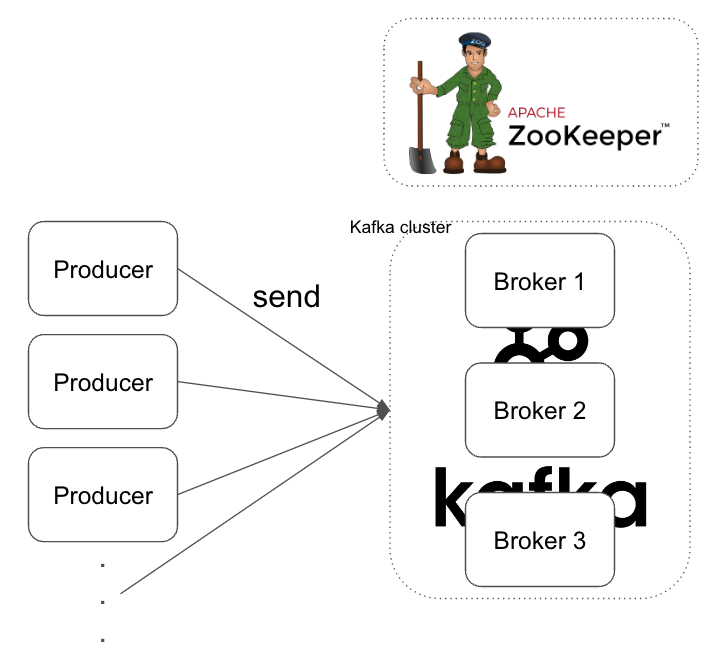
위 그림과 같이 Producer는 특정 애플리케이션 서버에서 기능을 개발해서 사용할 수 있습니다.
Java, Python, Go, Node 다양한 언어에서 라이브러리를 제공하고 있습니다.
상세한 Producer 기능은 다음 주제에 설명하겠습니다.
세그먼트(Segment)
카프카에서 세그먼트는 로그의 물리적인 파일 단위를 말합니다. 카프카는 토픽의 각 파티션을 로그로 관리하며 여러 개의 세그먼트 파일로 구성합니다.
세그먼트 파일은 4가지가 존재합니다.
- 00000000000000000000.index - 메시지의 오프셋을 빠르게 찾기 위한 파일
- 00000000000000000000.log - 실제 메시지 데이터가 저장된 파일(키, 값, 타임스탬프, 오프셋 등 정보가 포함)
- 00000000000000000000.timeindex - 특정 타임스탬프에 해당하는 메시지를 빠르게 찾기 위한 파일
- 00000000000000000000.leader-epoch-check-point - 파일은 리더 에포크 정보를 관리하여 클러스터 리밸런싱 및 리더 교체 시 파티션의 일관성을 유지
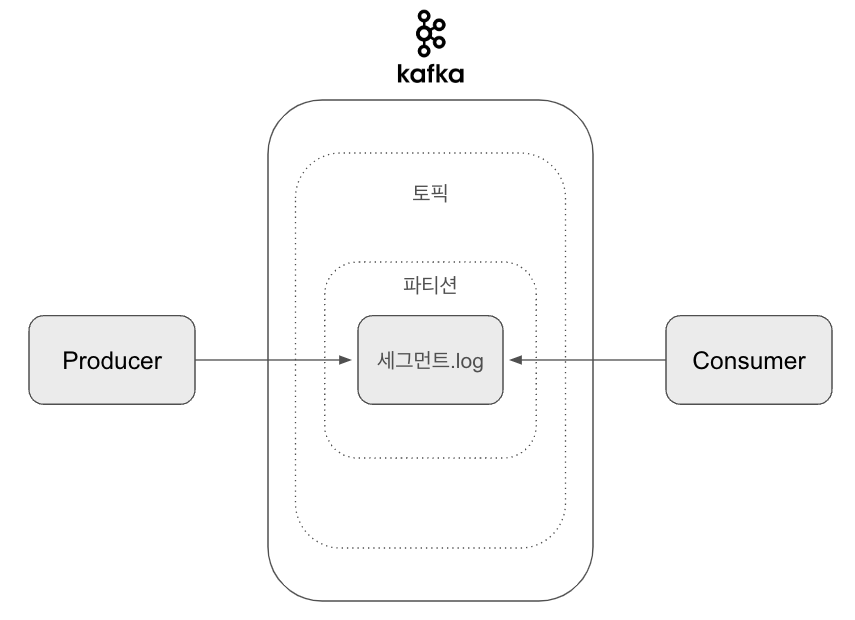
결과적으로 프로듀서가 전송한 메시지 정보를 세그먼트 로그에 저장하고 세그먼트 로그를 통해 컨슈머는 내가 컨슈밍 하고 있는데 파티션에 데이터를 가져가서 처리합니다.
추가적으로 카프카는 파일 읽기/쓰기를 하지만 어떻게 높은 처리량을 할 수 있을까요. 그 비법은 페이지 캐시라는 기능을 사용합니다.
페이지 캐시는 직접 디스크에 읽고 쓰는 대신 물리 메모리 중 애플리케이션이 사용하지 않는 일부 잔여 메모리를 활용해서 디스크 I/O에 대한 접근을 줄여 성능을 향상했습니다.
컨슈머(Consumer)
컨슈머는 카프카에서 메시지를 소비하는 역할을 합니다. 프로듀서가 메시지를 생성해서 브로커에 전송하면 해당 메시지를 가져와서 원하는 로직을 수행하는 역할을 컨슈머가 한다고 생각하시면 됩니다.
기본적으로 하나의 컨슈머는 하나의 파티션을 할당해서 처리합니다. 그렇기 때문에 중요한 건 파티션 수와 컨슈머 수는 1:1로 맵핑하는 게 좋습니다. 컨슈머 수가 많다고 해서 더 많은 처리를 하는 게 아닙니다.
(자세한 컨슈머 동작은 다른 주제에서 설명을 하겠습니다.)
이번 시간에는 카프카에 대한 아주 기초적이고 기본적인 내용들을 다뤄봤습니다.
다음 시간부터는 로컬환경에 실제 카프카를 설치 후 실습을 하면서 상세 내용들을 작성하겠습니다.
'백앤드(Back-End) > Kafka' 카테고리의 다른 글
| [Kafka] - Broker 리플리케이션(Replication) 동작 원리 (1) | 2024.10.15 |
|---|---|
| [Kafka] - Broker 메시지 복제와 커밋 ISR(In Sync Replica) (0) | 2024.08.02 |
| [Kafka] - Kafka Consumer 메시지 소비 (0) | 2024.08.02 |
| [Kafka] - Kafka Producer 메시지 생성 (0) | 2024.08.01 |
| [Kafka] - 로컬 개발 환경 구축 (1) | 2024.07.20 |


